 An Open-Source Library for Processing Documents using AI/ML in Apache Spark.
An Open-Source Library for Processing Documents using AI/ML in Apache Spark.
ScaleDP: Streamlined Document Processing with AI and Apache Spark
ScaleDP is an open-source library designed to simplify extracting structured data from unstructured documents using cutting-edge AI models. By leveraging the power of Apache Spark, ScaleDP provides scalable, high-performance document processing for tasks such as invoice extraction, scanned document processing, and real-time pipeline integration.
AI-Powered Document Processing
ScaleDP combines advanced pre-trained models like Large Language Models (LLMs), Vision Language Models (VLMs), and OCR engines to offer accurate and efficient data extraction from a variety of document types, including PDFs and images.
Scalable and High-Performance Processing
With its foundation built on Apache Spark, ScaleDP is capable of handling large-scale document processing. Whether you're working with thousands of invoices or need to process documents in real-time, ScaleDP scales effortlessly to meet your needs.
Key Features
Load PDFs and Images into Spark DataFrames: Use the built-in Spark PDF DataSource or load files as
binaryFilefor flexible document handling.Extract Text and Images: Extract text and images from PDFs and image files for further processing.
Zero-Shot Data Extraction: Use pre-trained LLMs and VLMs to extract structured data from text, images, and PDFs without custom training.
REST API Support: Run ScaleDP as a lightweight REST API for low-latency processing, even without a Spark session.
Streaming Mode: Process documents in real-time and integrate with event-driven architectures.
Hugging Face Integration: Access thousands of pre-trained models from the Hugging Face Hub or use your own custom models.
Quick Start
Installation
Prerequisites:
Python3.10 or higher
In case to run with Spark:
Apache Spark3.5 or higherJava8
Install the ScaleDP package with pip. Python package on pypi is scaledp:
pip install scaledp
Start a Spark session with ScaleDP
To begin using ScaleDP, start a Spark session with the following code:
from scaledp import *
spark = ScaleDPSession(with_spark_pdf=True)
spark
This initializes a Spark session with Spark PDF data source enabled.
Load a PDF File
Once your Spark session is ready, you can load a PDF file into a Spark DataFrame:
pdf_example = files('resources/pdfs/Invoice.pdf')
df = spark.read.format("pdf") \
.load(pdf_example)
df.show_image()
Output:
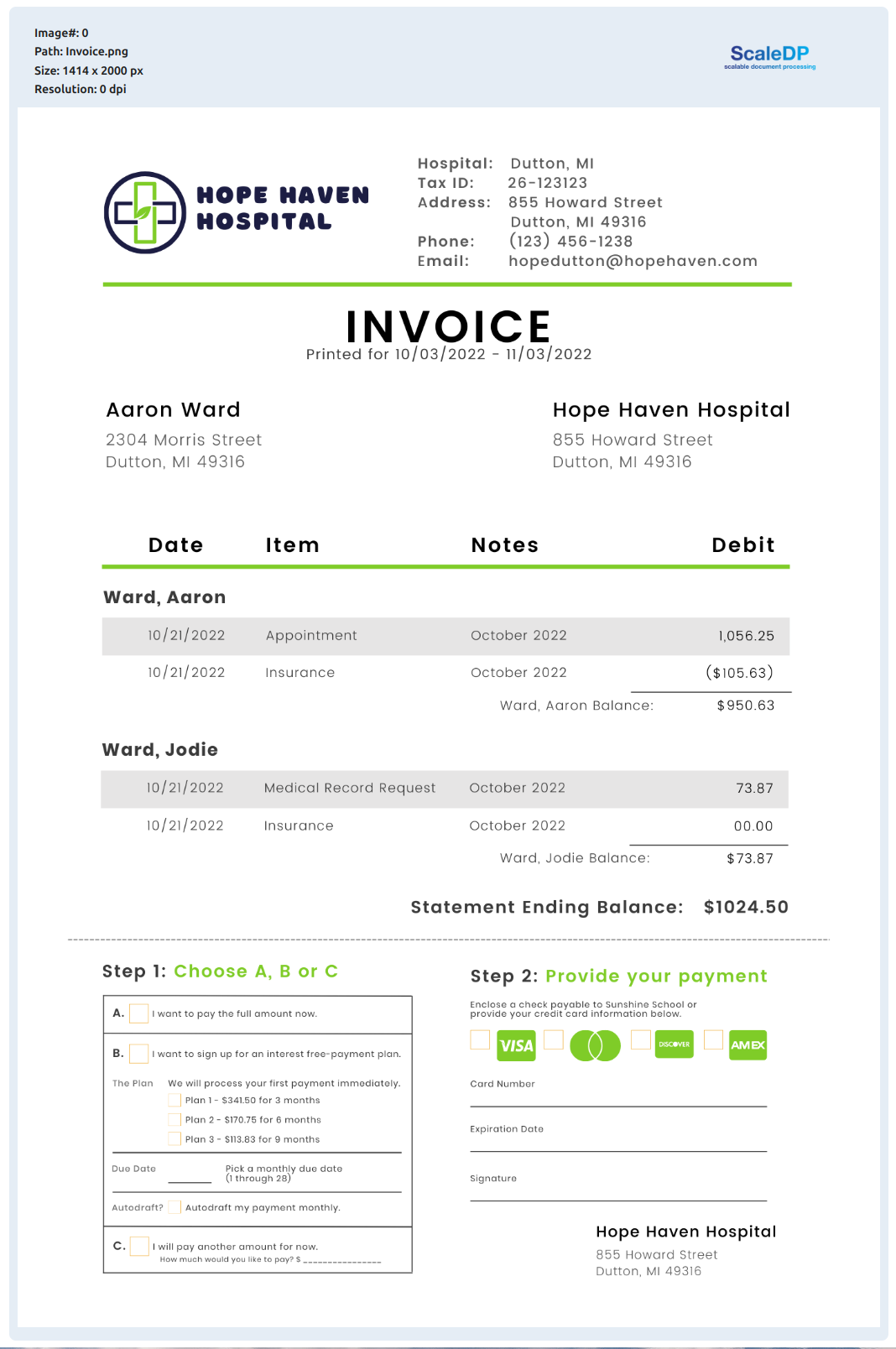
Zero-Shot data Extraction from the Image
from pydantic import BaseModel
import json
class Items(BaseModel):
date: str
item: str
note: str
debit: str
class InvoiceSchema(BaseModel):
hospital: str
tax_id: str
address: str
email: str
phone: str
items: list[Items]
total: str
pipeline = PipelineModel(stages=[
DataToImage(
inputCol="content",
outputCol="image"
),
LLMVisualExtractor(
inputCol="image",
outputCol="invoice",
model="gemini-1.5-flash",
apiKey="",
apiBase="https://generativelanguage.googleapis.com/v1beta/",
schema=json.dumps(InvoiceSchema.model_json_schema())
)
])
result = pipeline.transform(df).cache()
Show the extracted json:
result.show_json("invoice")
Generative AI Capabilities
ScaleDP leverages advanced AI/ML models to enhance document processing.
Here are some of its key capabilities:
LLM based OCR
- Accurate
- Multilingual
LLM Data Extraction from the text
- Zero-shot data extraction
- Declarative (possibility to define schema)
- Scalable
Visual LLM data extraction
- Extract data from the images
- Zero shot
- Accurate
- Declarative
LLM Ner
- Zero-shot NER
Supported OCR engines
Tesseract OCR
- Fast
- Most popular
Easy OCR
- Ready-to-use OCR with 80+ languages support.
Surya OCR
- OCR in 90+ languages that benchmarks favorably vs cloud services
- Line-level text detection in any language
DocTR OCR
- Optical Character Recognition made seamless & accessible to anyone, powered by TensorFlow 2 & PyTorch
Use Cases
Data Extraction
Extract structured data from invoices, receipts, or contracts. ScaleDP makes it easy to pull key information from unstructured documents, enabling automation of data entry and analysis workflows.
Real-Time Processing
Stream and process documents in real-time for event-driven applications. ScaleDP's streaming mode allows you to integrate document processing into real-time pipelines, perfect for applications like fraud detection or live data enrichment.
Research and Experimentation
Experiment with pre-trained models or fine-tune them for specific tasks. Whether you're testing new AI/ML models or customizing workflows, ScaleDP provides the flexibility to support your research and development efforts.
Why Choose ScaleDP?
- Scalability: Built on Apache Spark, ScaleDP handles large-scale document processing with ease, making it ideal for enterprise-level workloads.
- Flexibility: Supports multiple OCR engines and AI/ML models, allowing you to tailor the library to your specific use case.
- Ease of Use: Simple APIs and declarative workflows make it easy for developers to integrate and use ScaleDP in their projects.
- Open Source: Fully open-source and community-driven, ScaleDP is free to use and encourages collaboration and innovation.
- Advanced AI/ML Capabilities: Leverage state-of-the-art LLMs, VLMs, and OCR engines to extract, process, and analyze data with high accuracy.
- Real-Time and Batch Processing: Whether you need real-time streaming or batch processing, ScaleDP has you covered.
- Extensible: Easily integrate custom models or extend functionality to meet your unique requirements.
