Table of Contents

Spark PDF on Databricks
Machine Learning & Data Processing Expert
Great news. Spark PDF Data Source available to run on the Databricks. It was a long story and I spend about month for success this.
Main issue was with difference of the some classes beetwen community Apache Spark and Databricks Safe Spark.
I was filed issue to the Apache Spark Jira. Difference in one class and one month for fix it.
Thanks for Martin Grund and Alex Otter from the Databricks. They helped to update class in Databricks Safe Spark for able to run PDF Data Source on the Databricks envirenment.
So let's do it step by step now.
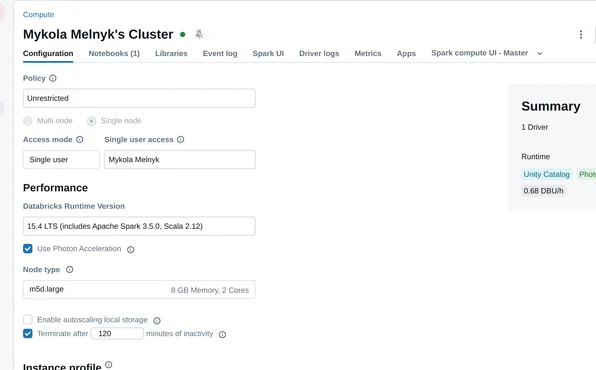
Create Cluster
I tested on Databricks runtime 15.4 and 16.0.
Let's create small single node cluster using 15.4 runtime:
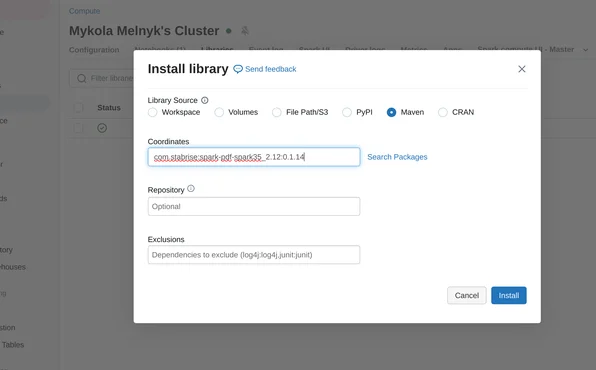
Install library
Need manually install Spark Pdf to the cluster.
Maven coordinates: com.stabrise:spark-pdf-spark35_2.12:0.1.16
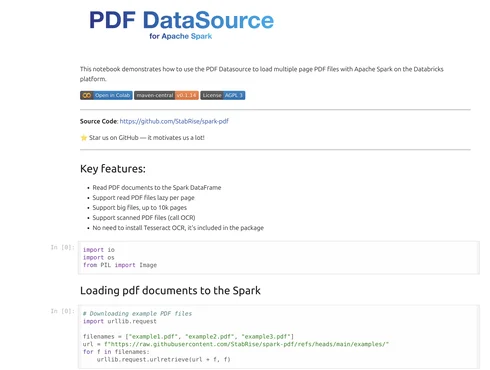
Load example notebook
I prepared notebook adapted and tested on the Databricks.
Run example
In this notebook we download few example pdf files from the Github store it to the workspace:
import urllib.request
filenames = ["./example1.pdf", "./example2.pdf", "./example3.pdf"]
url = f"https://raw.githubusercontent.com/StabRise/spark-pdf/refs/heads/main/examples/"for f in filenames:
urllib.request.urlretrieve(url + f.split("/")[-1], f)
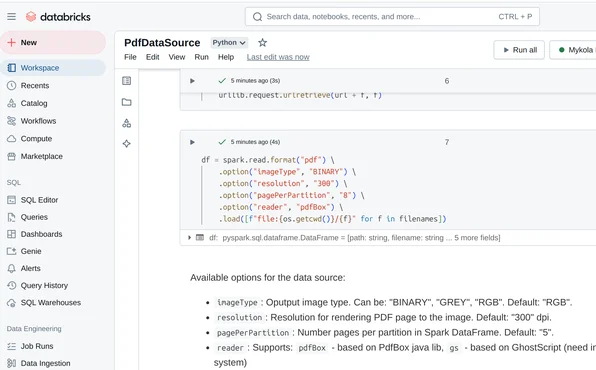
And read it using PDF DataSource:
df = spark.read.format("pdf") \
.option("imageType", "BINARY") \
.option("resolution", "300") \
.option("pagePerPartition", "8") \
.option("reader", "pdfBox") \
.load([f"file:{os.getcwd()}/{f}"for f in filenames])
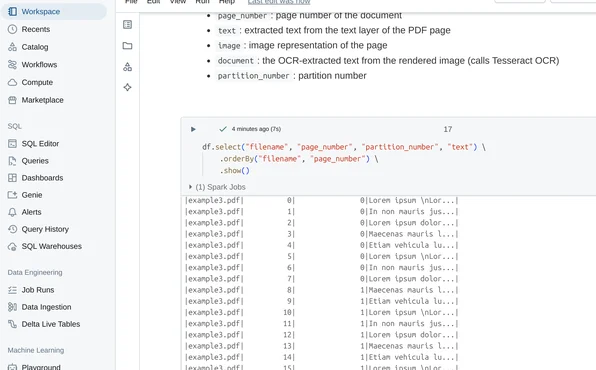
And here output: