
Read PDF files from the Databricks Unity Catalog volumes using Spark PDF Datasource
Mykola Melnyk
Machine Learning & Data Processing Expert
We improved support for the Databricks by adding support for the Unity Catalog in the Spark PDF Data Source.
So for now you can read PDF files from the Volumes in the Unity Catalog using Spark PDF Data Source.
Create Cluster
Spark PDF supports Databricks runtime 15.4 and above.
Install library
Need manually install Spark PDF library to the cluster.
Maven coordinates: com.stabrise:spark-pdf-spark35_2.12:0.1.16
Upload example files
Upload example files to the Databricks Unity Catalog Volume.
Read the PDF files using PDF DataSource
You can use both Scala and Python API(PySpark) to read PDF files from the Unity Catalog Volume.
Please specify your catalog and volume names in the code below:
Python
df = spark.read.format("pdf") \
.option("imageType", "BINARY") \
.option("resolution", "300") \
.option("pagePerPartition", "8") \
.option("reader", "pdfBox") \
.load(["/Volumes/{CATALOG_NAME}/default/{VOLUME_NAME}/*.pdf")
df.show()
Example output:
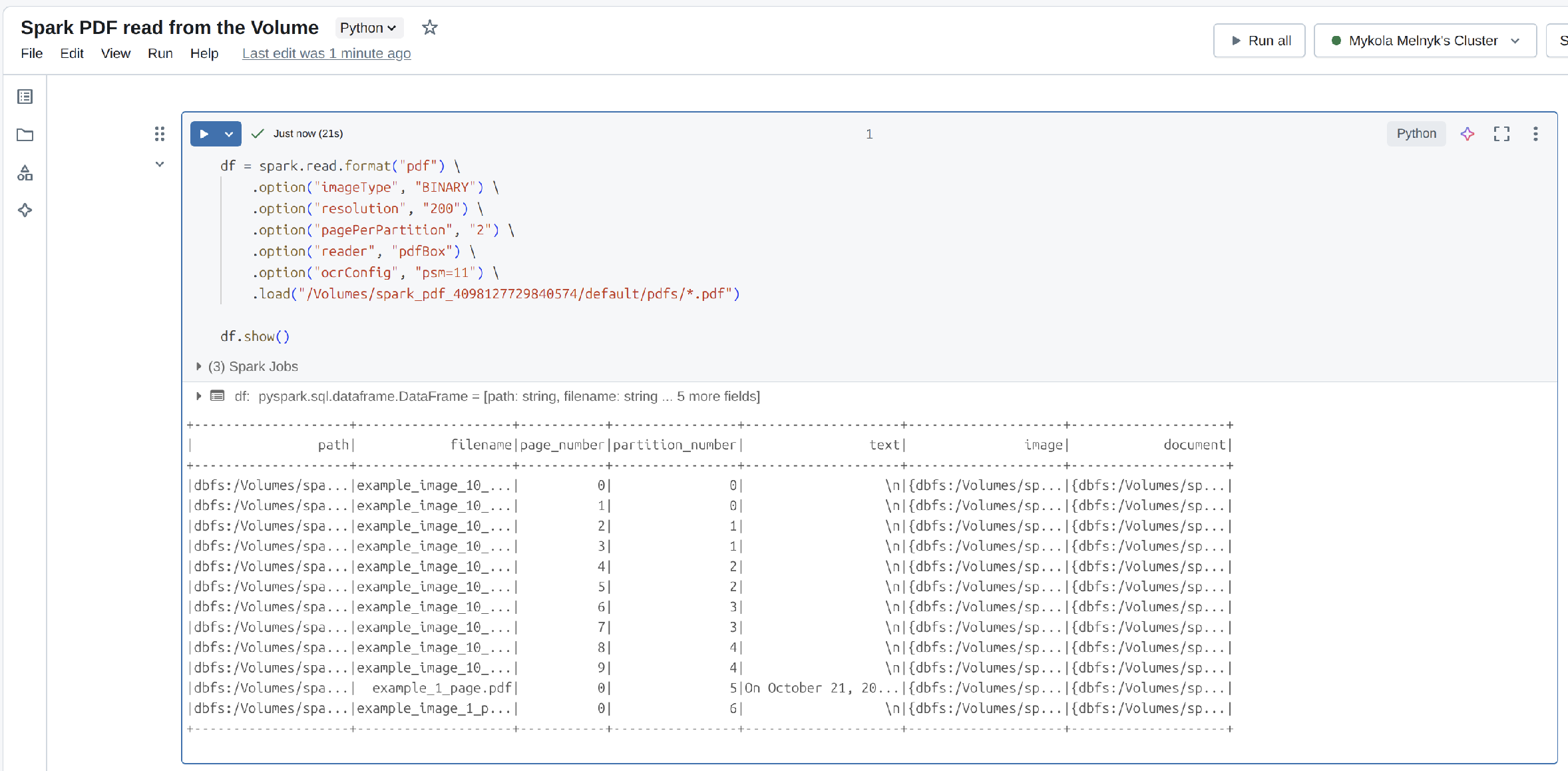
You can found full example in the notebook.